Overview

We introduce MOFA-Video, a method designed to adapt motions from different domains to the frozen Video Diffusion Model. By employing sparse-to-dense (S2D) motion generation and flow-based motion adaptation, MOFA-Video can effectively animate a single image using various types of control signals, including trajectories, keypoint sequences, AND their combinations.
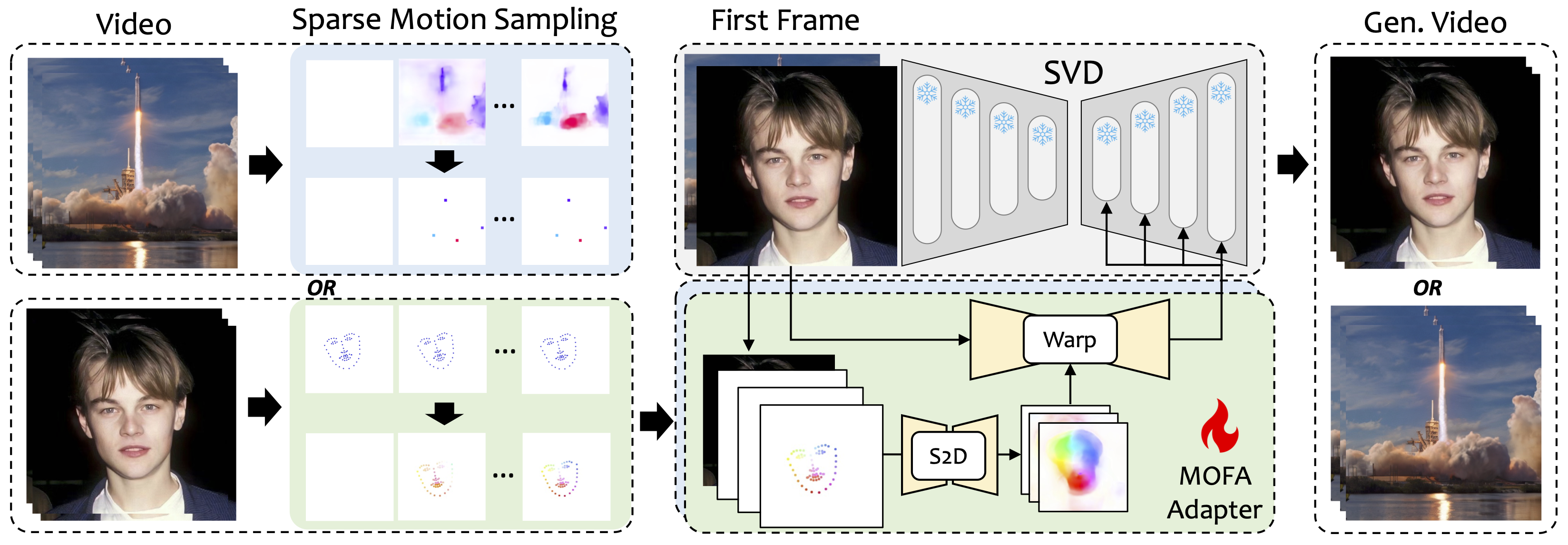
During the training stage, we generate sparse control signals through sparse motion sampling and then train different MOFA-Adapters to generate video via pre-trained SVD. During the inference stage, different MOFA-Adapters can be combined to jointly control the frozen SVD.